Geschichten rund um cyon & das Internet
-

- Autor & Kategorie:
- Philipp Zeder in Neuigkeiten
.swiss – Schweizer Domains jetzt auch für natürliche Personen
Seit Anfang 2016 kannst du Domains mit der Endung .swiss registrieren. Bislang allerdings nur, falls du einen passenden Handelsregistereintrag hast. Das ändert sich ab dem 24.04.2024. Neu können auch Privatpersonen Domainnamen mit der vom BAKOM verwalteten Endung registrieren. Allerdings steht .swiss nicht automatisch allen Privatpersonen zur Verfügung. Hier erfährst du, was die Voraussetzungen sind. Wer […]
0 -

- Autor & Kategorie:
- David Blum in Internet & Recht
KI-gesteuerte Videoproduktion: Entdecke das Kino der Zukunft
0 -
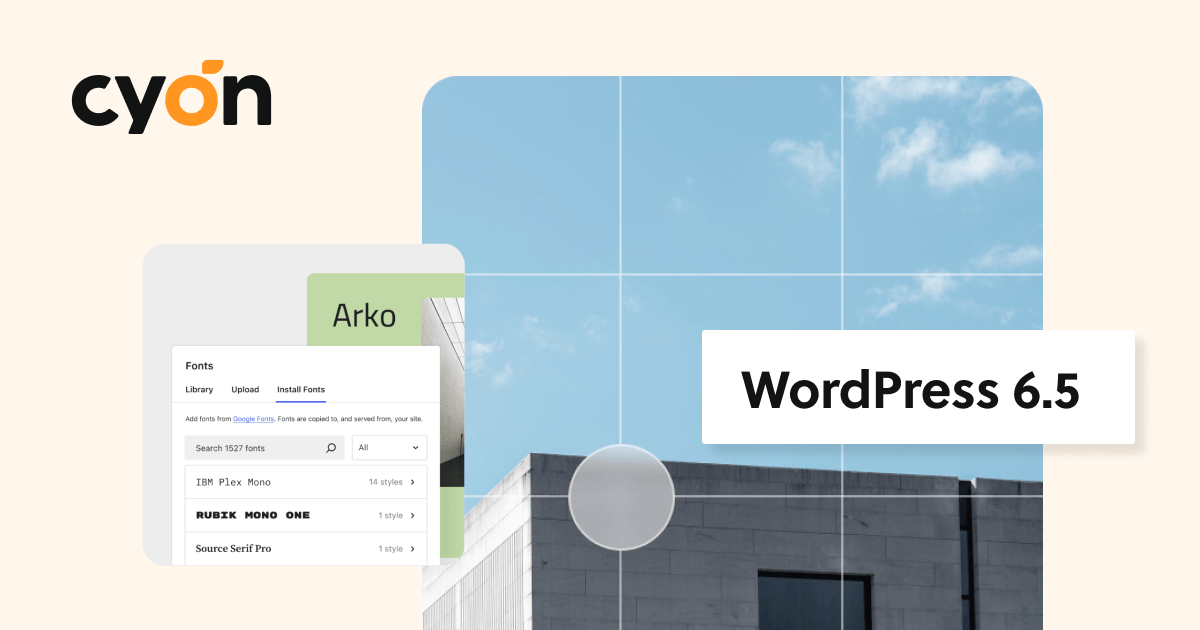
- Autor & Kategorie:
- Philipp Zeder in CMS & Co.
WordPress 6.5: Schriftarten-Bibliothek, verbesserte Versionshistorie & mehr
0 -

- Autor & Kategorie:
- Mona Sorcelli in CMS & Co.
TYPO3camp Schweiz 2024
10 -

- Autor & Kategorie:
- Martin Steiger in Internet & Recht
Bildrecht Schweiz: Bilder und Videos legal im Internet verwenden
4
Heiss diskutiert
Beliebte Beiträge
-
- Autor & Kategorie:
- Martin Steiger in Internet & Recht
Was bedeutet das neue Datenschutzrecht für Agenturen und Webmaster:innen in der Schweiz?
28 -
- Autor & Kategorie:
- David Blum in CMS & Co.
KI-Plugins für Blogger: Effizienter Content generieren in WordPress
8 -
- Autor & Kategorie:
- Mona Sorcelli in Über cyon
Geschichte: 20 Jahre cyon
272 -
- Autor & Kategorie:
- Philipp Zeder in Internet & Recht
Schöne Bilder frei nutzbar: Die besten Stockfoto-Websites 2024
23 -
- Autor & Kategorie:
- Tom Brühwiler in CMS & Co.
WordPress.com vs WordPress.org: Was ist der Unterschied?
4 -
- Autor & Kategorie:
- Nicolas Christakis in CMS & Co.
Weg von Google – eigener CalDAV- und CardDAV-Server mit Baïkal
58